Attention Is All You Need
| ~ 7 minutes read |
![]() source
source
Transformers have revolutionized the way we think of machine learning and is a foundational building block to nearly all state-of-the-art models.
I attempt to implement and explain the components to the transformer architecture.
What is a Transformer?
The transformer was first introduced in the seminal paper Attention Is All You Need. Although the paper’s original intention was for language translation tasks, it has since been used in all machine learning tasks (from computer vision to natural language processing), revolutionizing the landscape of ml.

Attention
The attention mechanism was first introduced in Neural Machine Translation By Jointly Learning To Align And Translate and Effective Approaches to Attention-based Neural Machine Translation.
Seq2seq
A Seq2seq model comprises of an encoder RNN and a decoder RNN. At each time step, the encoder takes in an input vector (word) from the sequence of inputs (sentence) and a hidden state. The encoder updates the hidden state and takes in the next input vector with the hidden state. This cycle repeats until the input sequence is fully ingested. The final hidden state is the context that is fed into the decoder which repeats the process of the encoder but outputs the output word vectors at each next time step.
The problem with Seq2seq models was that, for long input sequences, the fixed context vector, could not completely capture all the input. And, because the encoder preformed the hidden state calculations from left to right, the first word of the input sentence would be incrementally lost in the context vector as the hidden state is continually updated.
The solution to this bottleneck was the Attention mechanism which allows the decoder to attend to parts of the input sequence similar to how a human would scan back and forth from the source to target sentence when translating.
This was achieved using two improvements from the original Seq2seq model.
- The encoder would pass all hidden states to the decoder, not only the last hidden state, as the context.
- The decoder would calculate a score for each hidden state and focus only on the hidden states with a high score.
For a more indepth and visual explanation of the Attention mechanism, read the excellent post Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention) by Jay Alammar.
In the context of Transformers
In Attention Is All You Need, we abandon the idea of RNN’s and create a model (the Transformer) solely based on Attention… hence the title Attention Is All You Need.
In the paper, they introduce a new concept self-attention which is attention applied to each individual input vector with every other input vector including itself.

As we are encoding the word “it” in encoder #5 (the top encoder in the stack), part of the attention mechanism was focusing on “The Animal”, and baked a part of its representation into the encoding of “it”.
Scaled Dot-Product Attention
The actual attention formula is as follows: \(Attention(Q,K,V) = softmax(\dfrac{QK^T}{\sqrt{d_k}})V\)
As we can see, the Query matrix is multiplied by the transpose of the Key matrix. Then we divide (scale) by the scaling factor $\sqrt{d_k}$ where $d_k$ is the keys (and query) dimensionality. We perform a softmax and multiply the resulting matrix with the Value matrix.
We suspect that for large values of $d_k$, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients. To counteract this effect, we scale the dot products by $\dfrac{1}{\sqrt{d_k}}$. To illustrate why the dot products get large, assume that the components of $q$ and $k$ are independent random variables with mean 0 and variance 1. Then their dot product, $q·k=\Sigma_{i=1}^{d_k}q_ik_i$, has mean 0 and variance $d_k$.
Multi-Head Attention
Instead of using vector dot product to learn the weights of the model, we can create use matrices as projections to learn the weights to compute them in parallel.
The multiple heads of Multi-Head Attention can be thought of as kernels in Convolutional Neural Networks learning unique features of the sentence.
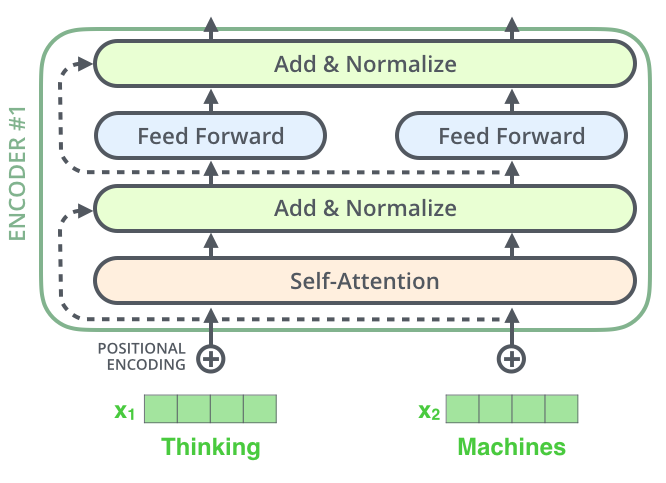
Encoder
The encoder comprises of 4 layers:
- Self-Attention
- First Layer-Normalization
- Feed Forward Neural Network
- Second Layer-Normalization
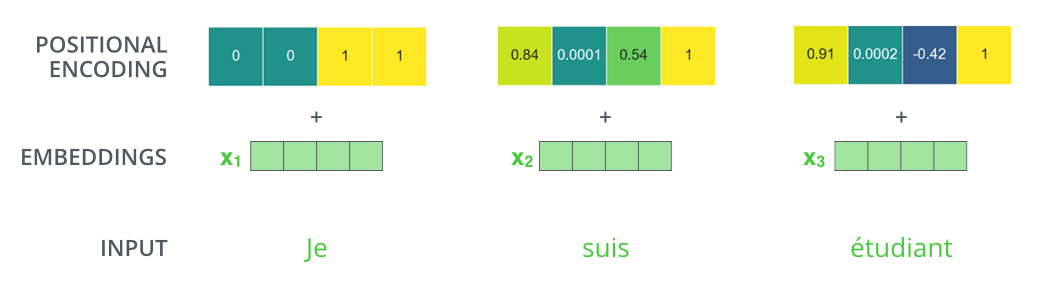
Positional Encoding
Naturally, due to the parallelism of Attention, the ordering of inputs is lost i.e. we lose the order of words in the input sentence. To account for this, we embed some positional information into the input embedding. This is done through an element-wise addition to the original embedding.
Decoder
The decoder is similar to the encoder however, contains an extra Attention and Layer-Norm layer for the K and V attention matrices from the encoder.
Once an output is generated, it is fed back into the decoder. We also mask future outputs so that the decoder does not attend to future (not yet generated) attention scores.
Masking
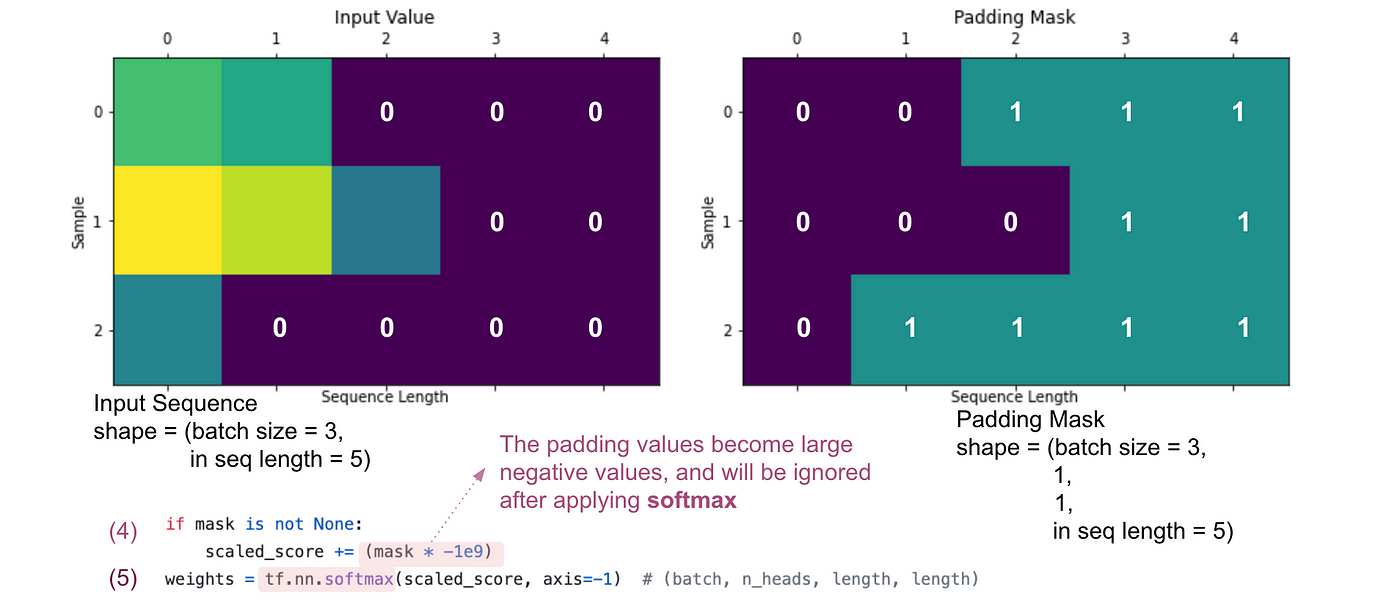
Masking can be found in the encoder and the decoder but for different reasons.
In the encoder, source sequence values may not match in length. Therefore, we apply padding to create a unified tensor size. We apply a padding mask to prevent our attention from attending to the 0 padding values.
In the decoder, the same padding mask is applied to the target sequence values to prevent attention on padding values. We also apply a subsequent mask to prevent our attention from attending to future values of the sequence which the model has not seen. This is so that the Transformer cannot cheat and output the value it sees next.
Padding
Creates a padding mask tensor by checking which values match the padding token pad_tok. The tensor’s size matches that of the input x.
def _create_pad_mask(self, x):
return (x != self.pad_tok).unsqueeze(-2)
Subsequent Mask
Creates a subsequent mask tensor by making values 0 in an upper triangle along and including the diagonal axis. The tensor’s size matches that of the input x.
def _create_subsequent_mask(self, x):
seq_len = x.size(1)
attention_shape = (1, seq_len, seq_len)
subsequent_mask = torch.triu(torch.ones(attention_shape), diagonal=1).type(torch.uint8)
return subsequent_mask == 0
Training
The original paper used an English-to-German translation dataset for training. I chose to use an English-to-French dataset to achieve similar results.
Dataset
Testing
Reference
- Attention Is All You Need
- The Illustrated Transformer
- tensor2tensor
- The Annotated Transformer
- Transformer Details Not Described in The Paper
- d2l - Attention Mechanisms and Transformers
- tunz/transformer-pytorch
- CS25 I Stanford Seminar - Transformers United 2023: Introduction to Transformers w/ Andrej Karpathy